Filligree2 years ago
One of my favorite gzip party tricks is that (ungzip (cat (gzip a) (gzip b))) == (cat a b). That is to say, the concatenation of two gzip streams is still a valid gzip file.
This hasn't ever been practically useful, but it means you can trivially create a 19-layer gzip file containing more prayer strips than there are atoms in the universe, providing a theological superweapon. All you need to do is write it to a USB-stick, then drop the USB-stick in a river, and you will instantly cause a heavenly crisis of hyperinflation.
mbreese2 years ago
In bioinformatics we use a modified gzip format called bgzip that exploits this fact heavily. The entire file is made of concatenated gzip chunks. Each chunk then contains the size of the chunk (stored in the gzip header). This lets you do random access inside the compressed blocks more efficiently.
Sadly, the authors hard coded the expected headers so it’s not fully gzip compatible (you can’t add your own arbitrary headers). For example, I wanted to add a chunk hash and optional encryption by adding my own header elements. But as the original tooling all expects a fixed header, it can’t be done in the existing format.
But overall it is easily indexed and makes reading compressed data pretty easy.
So, there you go - a practical use for a gzip party trick!
egorpv2 years ago
In such case, imo, it would be more appropriate to use ZIP container format which supports multiple independent entries (files) and index table (including sizes) for them. Compression algorithm is essentially the same (Deflate) so it would not be bloated in any way. As for practical implementations of serializing complex "objects" into ZIP, numpy [0] can be mentioned as an example.
[0] https://numpy.org/doc/stable/reference/generated/numpy.savez...
Arkanosis2 years ago
On top of enabling indexing, it reduces the amount of data lost in the event of data corruption — something you get for free with block-based compression algorithms like BWT-based bzip2 but is most of the time missing from dictionary-based algorithms like LZ-based gzip.
I don't think many people use that last property or are even aware of it, which is a shame. I wrote a tool (bamrescue) to easily recover data from uncorrupted blocks of corrupted BAM files while dropping the corrupted blocks and it works great, but I'd be surprised if such tools were frequently used.
mbreese2 years ago
Why do you think I wanted to add hashes and encryption at the block level? :)
I’ve had to do similar things in the past and it’s a great side-feature of the format. It’s a horrible feeling when you find a corrupted FASTQ file that was compressed with normal gzip. At least with bgzip corrupted files, you can find and start recovery from the next block.
0d0a2 years ago
Even if it doesn't use block-based compression, if there isn't a huge range of corrupted bytes, corruption offsets are usually identifiable, as you will quickly end up with invalid length-distance pairs and similar errors. Although, errors might be reported a few bytes after the actual corruption.
I was motivated some years ago to try recovering from these errors [1] when I was handling a DEFLATE compressed JSON file, where there seemed to be a single corrupted byte every dozen or so bytes in the stream. It looked like something you could recover from. If you output decompressed bytes as the stream was parsed, you could clearly see a prefix of the original JSON being recovered up to the first corruption.
In that case the decompressed payload was plaintext, but even with a binary format, something like kaitai-struct might give you an invalid offset to work from.
For these localized corruptions, it's possible to just bruteforce one or two bytes along this range, and reliably fix the DEFLATE stream. Not really doable once we are talking about a sequence of four or more corrupted bytes.
ynik2 years ago
Even cooler is that it's possible to create an infinite-layer gzip file: https://honno.dev/gzip-quine/
noirscape2 years ago
Is that by any chance related to how the TAR format was developed?
Considering the big thing with TAR is that you can also concatenate it together (the format is quite literally just file header + content ad infinitum; it was designed for tape storage - it's also the best concatenation format if you need to send an absolute truckloads of files to a different computer/drive since the tar utility doesn't need to index anything beforehand), making gzip also capable of doing the same logic but with compression seems like a logical followthrough.
Suppafly2 years ago
I assume tar came first just for grouping things together and then compression came out and they were combined together. That's why the unix tarballs were always tar.gz prior to gz having the ability to do both things.
fwip2 years ago
We use it at $dayjob to concatenate multi-GB gzipped files. We could decompress, cat, and compress again, but why spend the cycles?
Joker_vD2 years ago
> This hasn't ever been practically useful,
I used it a couple times to merge chunks of gzipped CSV together, you know, like "cat 2024-Jan.csv.gz 2024-Feb.csv.gz 2024-Mar.csv.gz > 2024-Q1.csv.gz". Of course, it only works when there is no column headers.
wwader2 years ago
I think the alpine package format do use this in combination with tar being similar https://wiki.alpinelinux.org/wiki/Apk_spec
Hakkin2 years ago
This is true for a few different compression formats, it works for bzip2 too. I've processed a few TBs of text via `curl | tar -xOf - | bzip2 -dc | grep` for tar files with lots of individually compressed bz2 files inside.
hansvm2 years ago
It's kind of nice whenever you find yourself in an environment where, for whatever reason, you need to split a payload before sending it. You just `ungzip cat *` the gzipped files you've collected on the other end.
blibble2 years ago
I've used this trick to build docker images from a collection of layers on the fly without de/recompression
kajaktum2 years ago
I think ZSTD is also like this.
userbinator2 years ago
Besides a persistent off-by-one error, and the use of actual trees instead of table lookup for canonical Huffman, this is a pretty good summary of the LZ+Huffman process in general; and in the 80s through the mid 90s, this combination was widely used for data compression, before the much more resource-intensive adaptive arithmetic schemes started becoming popular. It's worth noting that the specifics of DEFLATE were designed by Phil Katz, of PKZIP fame. Meanwhile, a competing format, the Japanese LZH, was chosen by several large BIOS companies for compressing logos and runtime code.
Note that real-world GZIP decoders (such as the GNU GZIP program) skip this step and opt to create a much more efficient lookup table structure. However, representing the Huffman tree literally as shown in listing 10 makes the subsequent decoding code much easier to understand.
Is it? I found the classic tree-based approach to become much clearer and simpler when expressed as a table lookup --- along with the realisation that the canonical Huffman codes are nothing more than binary numbers.
0823498723498722 years ago
I'd agree with TFA that canonical Huffman, although interesting, would be yet another thing to explain, and better left out of scope, but it does raise a question:
In what other areas (there must be many) do we use trees in principle but sequences in practice?
(eg code: we think of it as a tree, yet we store source as a string and run executables which —at least when statically linked— are also stored as strings)
mxmlnkn2 years ago
> In what other areas (there must be many) do we use trees in principle but sequences in practice?
Heapsort comes to mind first.
commandlinefan2 years ago
Author here! I actually did a follow-up where I looked at the table-based decoding: https://commandlinefanatic.com/cgi-bin/showarticle.cgi?artic...
yyyk2 years ago
>before the much more resource-intensive adaptive arithmetic schemes started becoming popular
The biggest problem was software-patent stuff nobody wanted to risk before they expired.
lifthrasiir2 years ago
The lookup table here would be indexed by a fixed number of lookahead bits, so it for example would duplicate shorter codes and put longer codes into side tables. So a tree structure, either represented as an array or a pointer-chasing structure would be much simpler.
jmillikin2 years ago
(2011)
Formatted version: https://infinitepartitions.com/cgi-bin/showarticle.cgi?artic...
PROMISE_2372 years ago
[dead]
Laiho2 years ago
If you prefer reading Python, I implemented the decompressor not too long ago: https://github.com/LaihoE/tiralabra
kuharich2 years ago
Past comments: https://news.ycombinator.com/item?id=6920822
solannouop2 years ago
Thanks a lot, how do you find this previous article so fast?
Lammy2 years ago
Click the domain name in parentheses to the right of the submission title.
hk13372 years ago
Why do people use gzip more often than bzip? There must be some benefit but I don’t really see it, you can split and join two bzipped files (presumably CSV so you can see the extra rows). Bzip seems to compress better than gzip too.
jcranmer2 years ago
Using gzip as a baseline, bzip2 provides only modest benefits: about a 25% improvement in compression ratio, with somewhat more expensive compression times (2-3×) and horrifically slow decompression times (>5×). xz offers a more compelling compression ratio (about 40-50% better), at the cost of extremely expensive compression time (like 20×), but comparable decompression time to gzip. zstd, the newest kid on the box, can achieve more slight benefits to compression ratio (~10%) at the same compression time/decompression time as gzip, but it's also tunable to give you as good results as xz (as slow as xz does).
What it comes down to is, if you care about compression time, gzip is the winner; if you care about compression ratio, then go with xz; if you care about tuning compression time/compression ratio, go with zstd. bzip2 just isn't compelling in either metric anymore.
umvi2 years ago
> at the same compression time/decompression time as gzip
In my experience zstd is considerably faster than gzip for compression and decompression, especially considering zstd can utilize all cores.
gzip is inferior to zstd in practically every way, no contest.
lxgr2 years ago
Practically, compatibility matters too, and it's hard to beat gzip there.
lifthrasiir2 years ago
The benefit from zstd is however so great that I even copied the zstd binary to some server I was managing but couldn't easily compile it from scratch. Seriously, bundling zstd binary is that worthy by now.
lxgr2 years ago
If you can control both sides, definitely go for it!
But in many cases, we unfortunately can't (gzip/Deflate is baked into tons of non-updateable hardware devices for example).
Too2 years ago
> if you care about compression time, gzip is the winner
Not at all. Lots of benchmarks show zstd being almost one order of magnitude faster, before even touching the tuning.
andrewf2 years ago
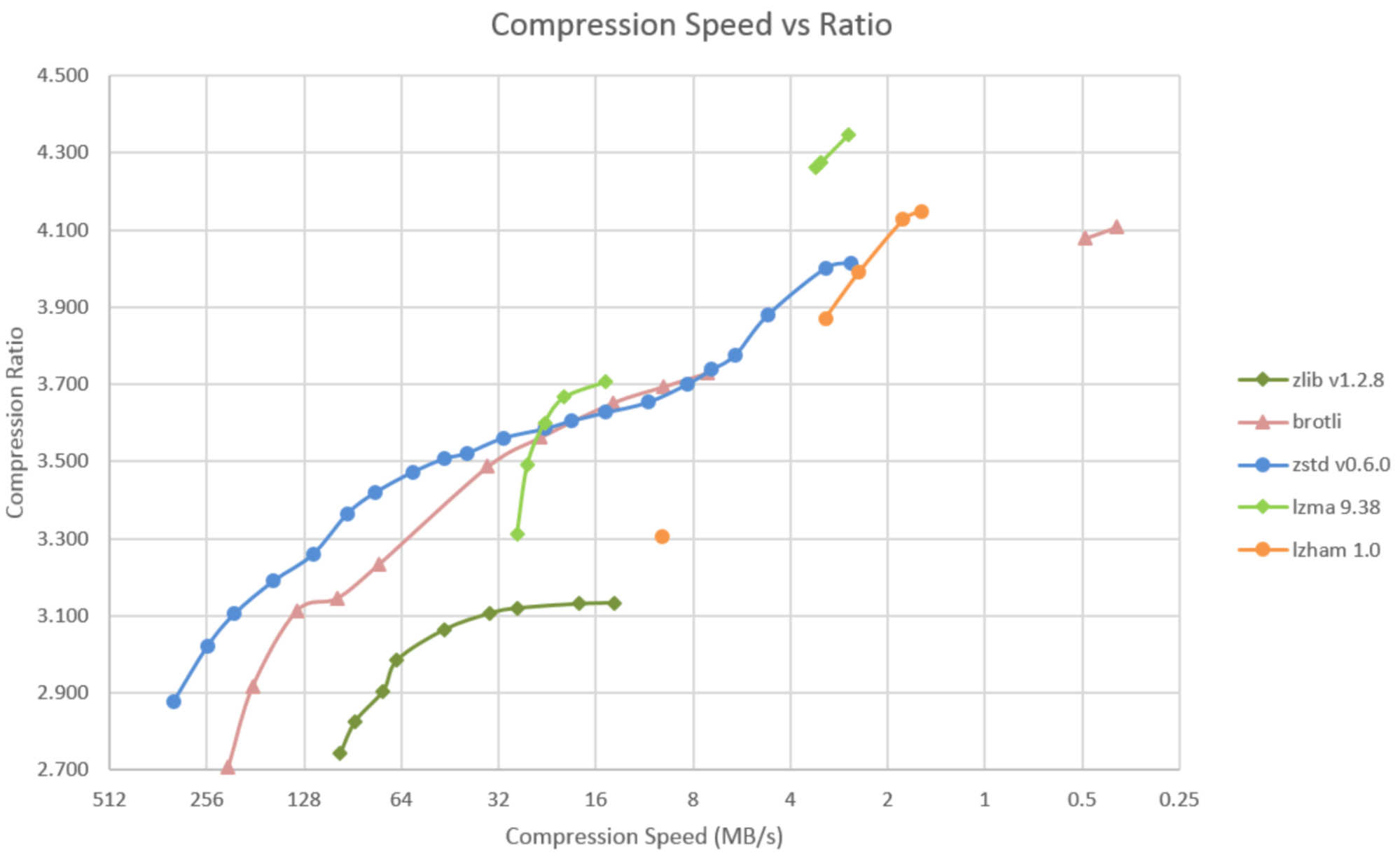
Adding to this: I like looking at graphs like https://calendar.perfplanet.com/images/2021/leon/image1.png . In this particular example, the "lzma" (ie xz) line crosses the zstd line, meaning that xz will be compress faster for some target ratios, zstd for others. Meanwhile zlib is completely dominated by zstd.
Different machines and different content will change the results, as will the optimization work that's gone into these libraries since someone made that chart in 2021.
PROMISE_2372 years ago
[dead]
rwmj2 years ago
Faster than most alternatives, good enough, but most importantly very widely available. Zstd is better on most axes (than bzip as well), except you can't be sure it's always there on every machine and in every language and runtime. zlib/gzip is ubiquitous.
We use xz/lzma when we need a compressed format that you can seek through the compressed data.
duskwuff2 years ago
bzip2 is substantially slower to compress and decompress, and uses more memory.
It does achieve higher compression ratios on many inputs than gzip, but xz and zstd are even better, and run faster.
masklinn2 years ago
TBF zstd runs most of the gamut, so depending on your settings you can have it run very fast at a somewhat limited level of compression or much lower at a very high compression.
Bzip is pretty completely obsolete though. Especially because of how ungodly slow it is to decompress.
duskwuff2 years ago
> TBF zstd runs most of the gamut
Yep. But bzip2 is much less flexible; reducing its block size from the default of 900 kB just reduces its compression ratio. It doesn't make it substantially faster; the algorithm it uses is always slow (both to compress and decompress). There's no reason to use it when zstd is available.
masklinn2 years ago
Oh I completely agree, as I said bzip2 is obsolete as far as I’m concerned.
I was mostly saying zstd is not just comparable to xz (as a slow but high-compression ratio format), it’s also more than competitive with gzip, if it’s available the default configuration (level 3) will very likely compress faster and use less CPU and yield a smaller file size than gzip, though I’m pretty sure it uses more memory to do that (because of the larger window if nothing else).
qhwudbebd2 years ago
I agree about the practical utility of bzip2. It's quite an interesting historical artefact, though, as it's the only one of these compression schemes that isn't dictionary-based. The Burrows-Wheeler transform is great fun to play with.
PROMISE_2372 years ago
[dead]
zie2 years ago
Muscle memory. We've been doing gzip for decades and we are too lazy to remember the zstd commands to tar, assuming the installed version of tar has been updated.
gloflo2 years ago
... --auto-compress ... foo.tar.zstd
zie2 years ago
That's cool! Is that a GNU tar only thing? Based on it being a longopt, I'm guessing a GNU tar only thing. That's the problem with these things, it takes a while to get pushed to all the installed copies of tar running around. Perhaps it's time to check:
* MacOS Sonoma(14.6) has tar --auto-compress and --zstd
* OpenBSD tar does not appear to have it: https://man.openbsd.org/tar
* FreeBSD does: https://man.freebsd.org/cgi/man.cgi?query=tar
qhwudbebd2 years ago
Both libarchive ("bsdtar") and GNU tar have -a, which I guess are the only two upstream tar implementations that are still relevant? You're right, it can take a while for these things to propagate downstream though.
zie2 years ago
Some of us use OpenBSD: https://man.openbsd.org/tar
qhwudbebd2 years ago
Ooh interesting. I'd assumed (incorrectly) that OpenBSD tar was just libarchive like FreeBSD and NetBSD. I prefer BSD libarchive tar to GNU tar as /bin/tar on my Linux machines too for what it's worth.
zie2 years ago
OpenBSD is fairly brutal on allowing third party dependencies into base. I'm sure there is a package for both libarchive and gnu tar(Haven't actually checked, but I'd be surprised if there is not).
PROMISE_2372 years ago
[dead]
PROMISE_2372 years ago
[dead]
PROMISE_2372 years ago
[dead]
oneshtein2 years ago
gzip is fast (pigz is even faster), supported everywhere (even in DOS), uses low amounts of memory, and compresses well enough for practical needs.
bzip2 is too slow.
xz is too complex (see https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=1068024 ), designed to compress .exe files.
lzip is good, but less popular.
zstd is good and fast, but less popular.
Spooky232 years ago
Another factor is that gzip is over 30 years old and ubiquitous in many contexts.
Zstd is awesome, but has only been around for a decade, but seems to be growing.
PROMISE_2372 years ago
[dead]
sgarland2 years ago
Parallel compression (pigz [0]) and decompression (rapidgzip [1]), for one. When you're dealing with multi-TB files, this is a big deal.
0823498723498722 years ago
Has anyone taken the coding as compression (when you create repeated behaviour, stuff it in the dictionary via creating a function; switching frameworks is changing initial dicts; etc.) metaphor seriously?
commandlinefan2 years ago
Sounds like LZW compression to me - is what you're thinking of different than that?
0823498723498722 years ago
Different in terms of applying the same principle to produce "semantically compressed" code — instead of having each new dictionary entry be a reference to an older one along with the new symbol, each new function will refer to older ones along with some new literal data.
(If that still doesn't make sense, see the sibling comment to yours.)
PROMISE_2372 years ago
[dead]
PROMISE_2372 years ago
[dead]
PROMISE_2372 years ago
[dead]
[deleted]2 years agocollapsed
{kind=link}